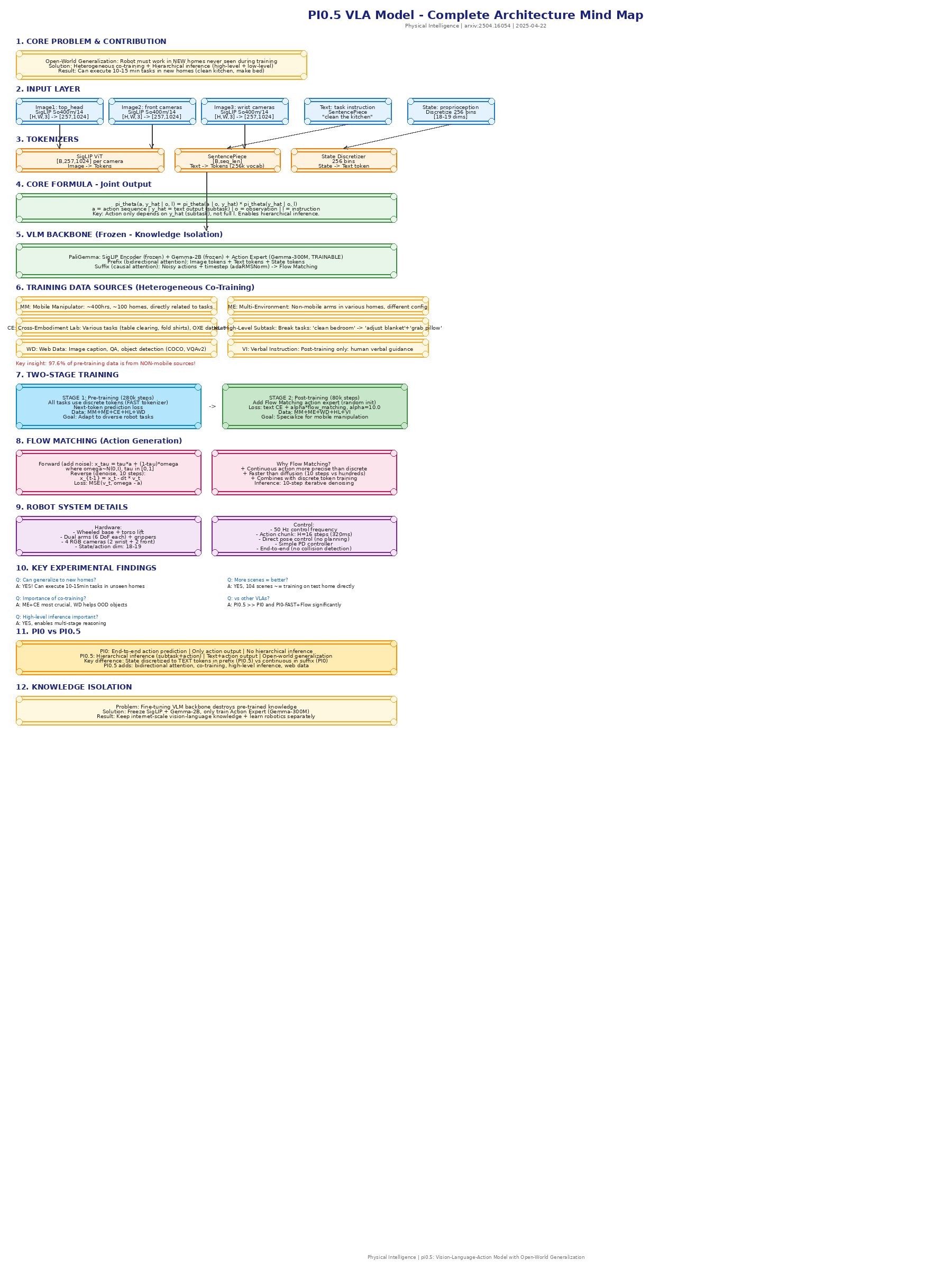
一、整体定位(核心问题)
开放世界泛化 (Open-World Generalization)
π₀.₅ 要解决的核心问题:机器人必须在从未见过的真实家庭环境中工作。
解决方案:异构任务协同训练 + 分层推理
- 来自其他机器人的数据
- 高级语义预测
- 人类口头指令
- 网络数据(图文对、问答、物体检测)
最终效果
能在全新房屋中执行 10-15 分钟 的长程任务,例如:清洁厨房、收拾卧室、挂毛巾、铺床
Physical Intelligence | Vision-Language-Action Model with Open-World Generalization
论文: arxiv.org/abs/2504.16054 | 2025-04-22π₀.₅ 要解决的核心问题:机器人必须在从未见过的真实家庭环境中工作。
能在全新房屋中执行 10-15 分钟 的长程任务,例如:清洁厨房、收拾卧室、挂毛巾、铺床
| 符号 | 含义 |
|---|---|
a |
动作序列 a_{t:t+H} |
ŷ |
输出的文本 token(高级子任务预测) |
o |
观测(图像 + 状态) |
l |
完整指令("拿起红色的杯子放到蓝色盒子里") |
关键洞察:动作分布仅依赖 ŷ 而非 l,实现分层推理。
o_t = [I_t¹, ..., I_tⁿ, q_t]
| 摄像头 | 说明 | 编码器 |
|---|---|---|
| top_head | 前置 | SigLIP So400m/14 |
| front_high | 高视角 | |
| cam_left | 左腕 | |
| cam_right | 右腕 |
关节角度 | 夹爪位姿 | 躯干升降 | 基座速度
状态处理:离散化(256 bins) → 作为文本token输入
完整任务提示 (High-level command): "收拾盘子" / "清洁厨房" / "铺床"
模型输出 ŷ (子任务预测): "拿起盘子" / "打开抽屉" / "放下衣物"
| 类型 | 模型 | 输出 |
|---|---|---|
| 图像 Tokenizer | SigLIP ViT | [B, 257, 1024] per camera |
| 文本 Tokenizer | SentencePiece | [B, seq_len] (256k 词表) |
| 状态 Tokenizer | 离散化 | 256 bins → text token |
传统 LLM (因果注意力): Token₁ → Token₂ → Token₃ → Token₄ → Token₅ 只能看到前面的 token π₀.₅ (双向注意力): Token ←→ Token ←→ Token ←→ Token ←→ Token 可以看到所有 token
| 数据源 | 说明 | 作用 |
|---|---|---|
| MM | Mobile Manipulator (~400小时, ~100家庭) | 直接相关于评估任务 |
| ME | Multi-Environment (非移动机械手) | 不同构型/场景迁移 |
| CE | Cross-Embodiment Lab (OXE数据集) | 跨任务迁移 |
| HL | High-Level Subtask Prediction | 子任务分解(如"打扫卧室"→"整理毯子") |
| WD | Web Data (COCO, VQAv2等) | 提升语义泛化能力 |
| VI | Verbal Instruction (口头指令) | 后训练阶段,人类指导 |
x^τ,ω = τ·a + (1-τ)·ω, ω~N(0,I)
1. 初始化: x₁ = random_noise
2. 迭代去噪 (10步):
for i in range(10):
τ = 1 - i/10
v_t = model(x_t, τ) # 预测噪声
x_{t-1} = x_t - dt * v_t # 欧拉更新
3. 最终 x₀ ≈ 预测的动作
L = ||v_t - (ω - a)||² = MSE(预测噪声, 真实噪声)✓ 能!在每个真实家庭中持续成功完成各种任务,任务持续2-5分钟,涉及多个阶段。
训练位置数量越多,泛化性能越好。104个位置训练的模型 ≈ 在测试家庭直接训练。
π₀.₅ >> π₀,即使给 π₀ 更长训练时间仍明显更好。
高级推理显著提升性能,帮助模型理解任务结构和场景语义。
问题:传统 VLA 微调会破坏预训练知识
效果:保持预训练的语义理解和视觉能力,同时学习细粒度动作控制。
| 特性 | π₀ | π₀.₅ |
|---|---|---|
| 状态处理 | 连续值 → suffix | 离散化 → prefix (文本token) |
| 输出 | 仅动作 | 文本(子任务) + 动作 |
| 注意力 | 因果注意力 | 双向注意力 |
| 高级推理 | 不支持 | 支持 (分层推理) |
| 协同训练 | 无 | 异构数据协同训练 |
| 泛化能力 | 有限 | 开放世界泛化 |
| 任务时长 | 短程 | 10-15分钟长程 |